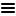We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
On the top, protein expression in current human tissue, based on all annotated cell types, is reported with the units not detected (n), low (l), medium (m) and high (h). Underneath, protein expression in each annotated cell type are reported using the same units.
Protein expression data is based on knowledge-based annotation. For genes where more than one antibody has been used, a collective score is set.
If knowledge-based annotation could not be performed for a gene, no data is displayed here. View antibody staining data further down this page.
No data
RNA expressioni
A summary of mRNA expression data available for current tissue based on several datasets. The mRNA expression levels in human tissues are based on RNA-seq data generated by the Human Protein Atlas (HPA), Genotype-Tissue Expression (GTEx) portal and CAGE data generated by the FANTOM5 consortium. Consensus normalized expression levels for human tissues was created by combining the data from HPA and GTEx datasets.
The mRNA expression levels in pig are based on RNA-seq data generated by the Human Protein Atlas (HPA), and for mouse, HPA data and in situ hybridization generated by the Allen brain atlas are reported.
Scroll down to view mRNA expression data in more detail.
Consensus:
1.6
nTPM
HPA:
0.7
nTPM
GTEx:
1.6
nTPM
FANTOM5:
1.2
Scaled Tags Per Million
SMALL INTESTINE - Annotated protein expression
Pending normal tissue analysis
SMALL INTESTINE - HPA RNA-seqi
The RNA-seq details section shows detailed information about the individual samples used for the transcript profiling and results of the RNA-seq analysis.
Information about each individual sample is listed below, including gender, age, a tissue section image and estimated fractions of cell types. nTPM (normalized transcripts per million) values give a quantification of the gene abundance which is comparable between different genes and samples.
Average nTPM
0.7
Male, age 65
Small intestine sample 232 nTPM: 0.7
Cell types%
Glandular cells:
55
Smooth muscle cells:
5
Other cell types:
40
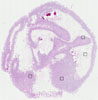
Male, age 39
Small intestine sample 233 nTPM: 0.6
Cell types%
Glandular cells:
40
Smooth muscle cells:
5
Other cell types:
55
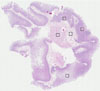
Male, age 68
Small intestine sample 234 nTPM: 0.5
Cell types%
Glandular cells:
30
Smooth muscle cells:
15
Other cell types:
55
Male, age 85
Small intestine sample 235 nTPM: 0.9
SMALL INTESTINE - GTEx RNA-seqi
RNA-Seq data generated by the Genotype-Tissue Expression (GTEx) project from human tissues is reported as mean nTPM. More information can be found on the GTEx portal.
Distribution across the dataset is visualized with box plots, shown as median and 25th and 75th percentiles. Points are displayed as outliers if they are above or below 1.5 times the interquartile range. nTPM values of the individual samples are presented next to the box plot.
Average nTPM
1.6
GTEx sample id
Sample description
nTPM
Small Intestine - Terminal Ileum Average nTPM: 1.6
Samples: 187
Max nTPM: 9.5
Min nTPM: 0.0
Std nTPM: 1.6
Median nTPM: 1.2
GTEX-13X6H-1826-SM-7EWCZ
50-59 years, female
9.5
GTEX-14BMU-1426-SM-5TDE5
20-29 years, female
9.1
GTEX-ZYFG-2026-SM-5E43Y
60-69 years, female
7.6
GTEX-WFG8-1626-SM-4LVMB
20-29 years, male
6.6
GTEX-183FY-1626-SM-793D8
20-29 years, male
6.4
GTEX-14XAO-1926-SM-6ETZO
60-69 years, female
5.1
GTEX-11NSD-1726-SM-5N9C3
20-29 years, male
4.9
GTEX-1QPFJ-2626-SM-DPRZU
30-39 years, female
4.9
GTEX-14PKV-2026-SM-6AJ9A
20-29 years, female
4.5
GTEX-X15G-1426-SM-4PQZK
50-59 years, female
4.5
GTEX-1J8QM-1026-SM-C1YQA
60-69 years, female
4.5
GTEX-XGQ4-1326-SM-4GIDU
50-59 years, male
4.3
GTEX-ZPCL-1726-SM-57WEO
60-69 years, female
4.2
GTEX-ZLV1-1126-SM-4WWBW
60-69 years, female
4.0
GTEX-1CB4F-1826-SM-7MGXI
60-69 years, male
4.0
GTEX-13FH7-1226-SM-5IJFK
50-59 years, female
3.9
GTEX-1QP28-1726-SM-E6CRK
50-59 years, female
3.9
GTEX-11P82-0826-SM-5P9GU
20-29 years, male
3.8
GTEX-VJYA-0926-SM-4KL1N
60-69 years, male
3.8
GTEX-139T6-1026-SM-5IJGC
50-59 years, male
3.6
GTEX-15G1A-1726-SM-6LPI4
30-39 years, male
3.6
GTEX-14PJ6-1726-SM-6AJBN
60-69 years, female
3.5
GTEX-WRHK-1026-SM-4MVOD
20-29 years, female
3.5
GTEX-ZXES-1526-SM-5NQ95
30-39 years, female
3.5
GTEX-1AMFI-1926-SM-731F2
50-59 years, female
3.4
GTEX-ZTX8-0526-SM-59HLD
20-29 years, male
3.4
GTEX-145LT-1026-SM-5LU9O
40-49 years, male
3.3
GTEX-11DXX-1626-SM-5H11H
60-69 years, female
3.2
GTEX-WFJO-0926-SM-4LVM2
30-39 years, male
3.2
GTEX-ZA64-1226-SM-5HL7B
20-29 years, male
3.1
GTEX-1399S-2026-SM-5KM4B
30-39 years, female
3.0
GTEX-14DAR-1426-SM-5RQIR
50-59 years, male
2.9
GTEX-1H1DE-1426-SM-9JGHV
20-29 years, male
2.8
GTEX-14PKU-1626-SM-6871C
40-49 years, female
2.7
GTEX-1AX8Z-2526-SM-731E3
60-69 years, male
2.7
GTEX-1JN76-1126-SM-C1YRL
20-29 years, female
2.7
GTEX-133LE-1426-SM-5IFH1
20-29 years, female
2.5
GTEX-ZTPG-2626-SM-57WFX
20-29 years, female
2.5
GTEX-1LBAC-1526-SM-CXZKU
20-29 years, male
2.5
GTEX-11I78-1126-SM-5A5K5
50-59 years, female
2.4
GTEX-16A39-1426-SM-6LLI6
30-39 years, female
2.4
GTEX-WH7G-1626-SM-4LVMY
40-49 years, male
2.4
GTEX-1HSMQ-2226-SM-C1YRD
50-59 years, male
2.4
GTEX-1IKOE-1926-SM-ARU7V
30-39 years, female
2.4
GTEX-1J8Q3-2526-SM-CNNQ4
60-69 years, male
2.4
GTEX-1JK1U-1226-SM-CNNPN
60-69 years, male
2.4
GTEX-1RAZQ-2226-SM-DPRZR
30-39 years, male
2.4
GTEX-1122O-1326-SM-5H11F
60-69 years, female
2.3
GTEX-14PJN-0826-SM-686ZL
30-39 years, male
2.3
GTEX-1C475-1426-SM-793CH
40-49 years, female
2.3
GTEX-ZVP2-1726-SM-5GU5P
50-59 years, male
2.3
GTEX-13PL7-2626-SM-5IFH4
60-69 years, female
2.2
GTEX-131XG-1726-SM-5LZUR
50-59 years, female
2.1
GTEX-XAJ8-0526-SM-47JYK
40-49 years, male
2.1
GTEX-YB5E-1526-SM-5IFIE
40-49 years, male
2.1
GTEX-ZEX8-1826-SM-57WBH
50-59 years, male
2.1
GTEX-13QBU-1926-SM-5IJEW
40-49 years, female
2.0
GTEX-144GM-1026-SM-79OKU
20-29 years, male
2.0
GTEX-ZP4G-1626-SM-57WGD
20-29 years, female
2.0
GTEX-1399R-2026-SM-5K7WN
30-39 years, male
1.9
GTEX-14PN3-2026-SM-68729
60-69 years, female
1.9
GTEX-Y9LG-1626-SM-5IFHM
30-39 years, male
1.9
GTEX-ZTSS-0926-SM-59865
40-49 years, male
1.9
GTEX-ZVT2-2126-SM-5NQ93
50-59 years, female
1.9
GTEX-ZVZP-1826-SM-5GZXB
50-59 years, male
1.9
GTEX-11P7K-1626-SM-5GU63
30-39 years, male
1.8
GTEX-WQUQ-2426-SM-4MVNW
60-69 years, male
1.8
GTEX-1OJC3-1626-SM-E9U65
20-29 years, male
1.8
GTEX-1B8KE-1726-SM-7IGMN
50-59 years, male
1.7
GTEX-1RAZA-1826-SM-DTXA2
20-29 years, male
1.7
GTEX-11XUK-1426-SM-5EQMG
40-49 years, female
1.6
GTEX-1399U-2126-SM-5IFEZ
50-59 years, female
1.6
GTEX-139YR-2226-SM-5IFFW
50-59 years, male
1.6
GTEX-VUSG-1726-SM-4KKZL
50-59 years, male
1.6
GTEX-145ME-0926-SM-5O9AR
40-49 years, female
1.5
GTEX-1GMR2-1026-SM-7MKHJ
50-59 years, male
1.5
GTEX-WY7C-1826-SM-4ONCE
50-59 years, male
1.5
GTEX-ZC5H-2326-SM-4WAYT
40-49 years, female
1.5
GTEX-ZZ64-0526-SM-5GZXM
20-29 years, male
1.5
GTEX-1KXAM-2026-SM-DHXKI
60-69 years, male
1.5
GTEX-13CF3-1226-SM-5LZXN
60-69 years, female
1.4
GTEX-1C64O-2526-SM-79ONO
60-69 years, male
1.4
GTEX-1PDJ9-1826-SM-E9U66
20-29 years, male
1.4
GTEX-12BJ1-1926-SM-5HL9Z
60-69 years, male
1.3
GTEX-13D11-0726-SM-5LZZB
50-59 years, female
1.3
GTEX-Y3IK-1726-SM-4YCCR
50-59 years, female
1.3
GTEX-ZLFU-1526-SM-4WWBT
40-49 years, male
1.3
GTEX-1LGOU-1426-SM-D3L8N
20-29 years, female
1.3
GTEX-11VI4-1626-SM-5EQKO
40-49 years, female
1.2
GTEX-131XF-1326-SM-5GCMQ
60-69 years, male
1.2
GTEX-14PK6-1626-SM-6871I
70-79 years, female
1.2
GTEX-XUZC-1426-SM-4BRV3
30-39 years, female
1.2
GTEX-YFCO-1326-SM-664NV
40-49 years, male
1.2
GTEX-Z9EW-0926-SM-5CVMM
40-49 years, male
1.2
GTEX-11EQ9-1326-SM-5985X
30-39 years, male
1.1
GTEX-13113-1226-SM-5EGHT
60-69 years, female
1.1
GTEX-13RTK-0826-SM-5Q5C6
20-29 years, male
1.1
GTEX-16NGA-1126-SM-7KFSY
40-49 years, female
1.1
GTEX-WEY5-1526-SM-4LMJF
40-49 years, female
1.1
GTEX-X5EB-1626-SM-4E3IV
40-49 years, male
1.1
GTEX-11TUW-1926-SM-5BC58
60-69 years, male
1.0
GTEX-1GL5R-2026-SM-7MKHP
50-59 years, male
1.0
GTEX-WFG7-1726-SM-4LVME
20-29 years, male
1.0
GTEX-ZF29-1626-SM-4WKFJ
60-69 years, female
1.0
GTEX-1QW4Y-1226-SM-EWRMY
30-39 years, male
1.0
GTEX-ZLWG-1626-SM-DNZZ1
50-59 years, female
1.0
GTEX-1EMGI-2826-SM-7IGMR
60-69 years, male
0.9
GTEX-1R9K5-2026-SM-E6CPS
50-59 years, male
0.9
GTEX-13FTW-2026-SM-5IJE2
40-49 years, male
0.8
GTEX-1497J-1926-SM-5TDCC
60-69 years, male
0.8
GTEX-1CAMS-2426-SM-7DHMV
40-49 years, female
0.8
GTEX-YEC4-1726-SM-4W21E
40-49 years, male
0.8
GTEX-ZQG8-2526-SM-57WEQ
60-69 years, female
0.8
GTEX-1H11D-2526-SM-9JGGU
40-49 years, male
0.8
GTEX-ZG7Y-1926-SM-DNZZ5
50-59 years, male
0.8
GTEX-1CAMR-0826-SM-7MKFK
20-29 years, male
0.7
GTEX-UPK5-2026-SM-4JBIM
40-49 years, male
0.7
GTEX-ZPIC-2326-SM-57WDW
40-49 years, female
0.7
GTEX-1NSGN-2126-SM-DPRYN
50-59 years, male
0.7
GTEX-1PIEJ-1526-SM-E6CP8
20-29 years, female
0.7
GTEX-1S82Z-1826-SM-E9TIK
30-39 years, female
0.7
GTEX-ZDTT-1726-SM-5HL69
60-69 years, male
0.7
GTEX-14C39-1826-SM-5ZZW4
40-49 years, male
0.6
GTEX-15DZA-0826-SM-6AJBF
30-39 years, female
0.6
GTEX-1GMR3-2726-SM-7MKFB
40-49 years, male
0.6
GTEX-XXEK-1026-SM-4BRUW
50-59 years, male
0.6
GTEX-15EU6-1826-SM-7PC1W
50-59 years, male
0.6
GTEX-1MUQO-2426-SM-EAZ5A
60-69 years, male
0.6
GTEX-1R7EU-1326-SM-E6CQ6
60-69 years, male
0.6
GTEX-111CU-1326-SM-5NQ8L
50-59 years, male
0.5
GTEX-13111-1426-SM-5DUW3
50-59 years, male
0.5
GTEX-16AAH-1426-SM-7KFTR
50-59 years, male
0.5
GTEX-16MTA-1526-SM-6LPJB
50-59 years, male
0.5
GTEX-17MFQ-1026-SM-7KFSZ
20-29 years, male
0.5
GTEX-18A66-2526-SM-7KFTZ
60-69 years, male
0.5
GTEX-1B8KZ-1126-SM-7IGLX
50-59 years, male
0.5
GTEX-1R9K4-2326-SM-E6CRB
60-69 years, male
0.5
GTEX-111YS-1426-SM-5GID8
60-69 years, male
0.4
GTEX-117YX-0326-SM-5GICL
50-59 years, male
0.4
GTEX-11DXZ-1326-SM-5H11X
50-59 years, male
0.4
GTEX-12WSK-1526-SM-5CVNO
40-49 years, female
0.4
GTEX-148VJ-2226-SM-5NQ9M
70-79 years, male
0.4
GTEX-14E6E-1626-SM-5RQI7
30-39 years, male
0.4
GTEX-WHSB-1026-SM-4M1XN
50-59 years, male
0.4
GTEX-XPVG-1726-SM-4B65W
50-59 years, male
0.4
GTEX-Y114-1426-SM-4TT6W
50-59 years, female
0.4
GTEX-YF7O-1826-SM-5IFIU
50-59 years, male
0.4
GTEX-1R9PM-1626-SM-DPRY9
20-29 years, male
0.4
GTEX-13W3W-2026-SM-5K7UL
60-69 years, female
0.3
GTEX-ZAB5-1526-SM-5HL9P
50-59 years, male
0.3
GTEX-1I1GT-1826-SM-ARZLW
60-69 years, female
0.3
GTEX-1RAZR-1826-SM-E6CRE
40-49 years, male
0.3
GTEX-11LCK-1926-SM-5A5KE
30-39 years, male
0.2
GTEX-13O61-1326-SM-5KM31
60-69 years, male
0.2
GTEX-18QFQ-1626-SM-72D7H
30-39 years, male
0.2
GTEX-ZQUD-0926-SM-57WE3
30-39 years, male
0.2
GTEX-1K9T9-2726-SM-D4P3E
50-59 years, female
0.2
GTEX-1MGNQ-2326-SM-EV7BG
40-49 years, male
0.2
GTEX-1R9JW-1926-SM-EVR4J
30-39 years, female
0.2
GTEX-1S5ZA-1326-SM-EV7BB
20-29 years, male
0.2
GTEX-1192X-2526-SM-59868
50-59 years, male
0.1
GTEX-13NYB-1826-SM-5J1N3
40-49 years, male
0.1
GTEX-13OVI-1926-SM-5IJCG
60-69 years, female
0.1
GTEX-17HHE-1726-SM-79OKT
50-59 years, male
0.1
GTEX-17KNJ-1626-SM-718AL
50-59 years, male
0.1
GTEX-WFON-1526-SM-4LVMP
40-49 years, male
0.1
GTEX-WYJK-1526-SM-4ONCW
50-59 years, male
0.1
GTEX-XBED-1426-SM-4AT4G
60-69 years, male
0.1
GTEX-XMK1-1826-SM-4B66F
40-49 years, male
0.1
GTEX-Y5V5-1826-SM-4VDS5
60-69 years, female
0.1
GTEX-ZF2S-1726-SM-57WFT
50-59 years, female
0.1
GTEX-1F75I-2526-SM-9WPOZ
40-49 years, male
0.1
GTEX-1JJE9-2226-SM-CXZJM
70-79 years, male
0.1
GTEX-1LH75-1926-SM-DIPGD
50-59 years, female
0.1
GTEX-1OKEX-1126-SM-DTXEB
60-69 years, male
0.1
GTEX-1R7EV-1226-SM-DTX82
40-49 years, male
0.1
GTEX-131XE-0926-SM-5HL7J
50-59 years, male
0.0
GTEX-13O21-1026-SM-5IJDU
50-59 years, male
0.0
GTEX-14PJ3-1326-SM-664O7
50-59 years, male
0.0
GTEX-1BAJH-2526-SM-7IGOT
70-79 years, male
0.0
GTEX-Y111-2226-SM-4SOJB
50-59 years, male
0.0
GTEX-Y3I4-1326-SM-4TT8Z
50-59 years, male
0.0
GTEX-Y5LM-1626-SM-4VDTB
40-49 years, female
0.0
GTEX-1JMQK-2426-SM-CXZJU
60-69 years, male
0.0
GTEX-1L5NE-1826-SM-EV79T
50-59 years, male
0.0
GTEX-1QCLZ-2126-SM-EWRNC
60-69 years, female
0.0
GTEX-1QP2A-2426-SM-EXOJA
50-59 years, male
0.0
Show allShow less
SMALL INTESTINE - FANTOM5 CAGEi
RNA expression in human tissues obtained through Cap Analysis of Gene Expression (CAGE) generated by the FANTOM5 project are reported as Scaled Tags Per Million.

 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded