We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
The antibodies are designated mAB for monoclonal and pAb for polyclonal.
pAb
Concentration
0.0325 mg/ml
Purity
Affinity purified using the PrEST-antigen as affinity ligand
Released in versioni
The release of the Human Protein Atlas in which the antibody was first published.
16.0
Validation summaryi
All assays through which the antibody has been validated. Here are more detailed descriptions of the IHC, ICC, WB and PA assays. The pie-charts indicate degree of validation in the different assays (IHC, ICC, WB and PA.
Immunocytochemistry is used to validate the antibody staining and for assessing and validating the protein expression pattern in selected human cell lines.
Validationi
Results of validation by standard or enhanced validation.
Standard validation is based on concordance with available experimental gene/protein characterization data in the UniProtKB/Swiss-Prot database. Standard validation results in scores Supported, Approved or Uncertain.
Enhanced validation is performed using either siRNA knockdown, tagged GFP cell lines or independent antibodies. For the siRNA validation the decrease in antibody-based staining intensity upon target protein downregulation is evaluated. For the GFP validation the signal overlap between the antibody staining and the GFP-tagged protein is evaluated. For the independent antibodies validation the evaluation is based on comparison of the staining of two (or more) independent antibodies directed towards independent epitopes on the protein.
For all cases except the siRNA validation, an image representative of the antibody staining pattern is shown. For the siRNA validation, a box plot of the results is shown.
Supportedi
Reliability scores for antibodies used in immunocytochemistry are set by comparing the staining pattern in cell lines with external experimental evidence for protein localization. The scores are termed Supported, Approved and Uncertain.
The subcellular location is supported by literature.
Immunofluorescent staining of human cell line SiHa shows localization to nucleoplasm.
Antibody dilution
human cell lines: HEK293 fixed with PFA, dilution: 1:8 human cell lines: SiHa fixed with PFA, dilution: 1:8 human cell lines: U2OS fixed with PFA, dilution: 1:8
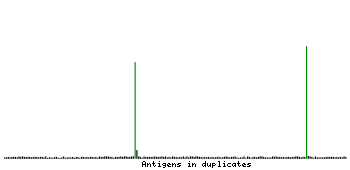
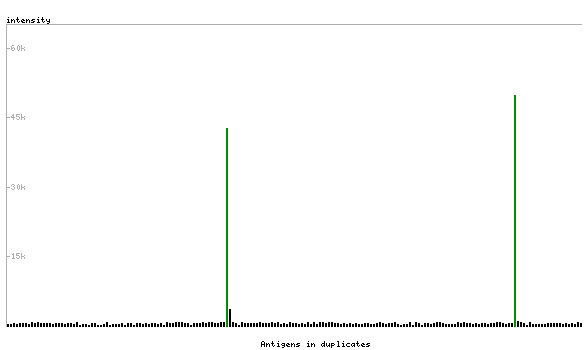
PROTEIN ARRAY
Validationi
A protein array containing 384 different antigens including the antibody target is used to analyse antibody specificity. Depending on the array interaction profile the antibody is scored as Supported, Approved, or Uncertain.
Supported
Pass with single peak corresponding to interaction only with its own antigen.
Antibody specificity analysis with protein arrays. Predicted and matching interactions are shown in green.
The ProteinBrowser displays the antigen location on the target protein(s) and the features of the target protein. Transcript names and schematic transcript structures including exons, introns and UTRs for the different isoforms are shown on top, and can be used to switch between the structures for the different splice variants.
At the top of the view, the position of the antigen (identified by the corresponding HPA identifier) is shown as a green bar. A yellow triangle on the bar indicates a <100% sequence identity to the protein target.
Below the antigens, the maximum percent sequence identity of the protein to all other proteins from other human genes is displayed, using a sliding window of 10 aa residues (HsID 10) or 50 aa residues (HsID 50). The region with the lowest possible identity is always selected for antigen design, with a maximum identity of 60% allowed for designing a single-target antigen (read more).
The curve in blue displays the predicted antigenicity i.e. the tendency for different regions of the protein to generate an immune response, with peak regions being predicted to be more antigenic.The curve shows average values based on a sliding window approach using an in-house propensity scale. (read more).
Signal peptides (turquoise) and membrane regions (orange) based on predictions using the
majority decision methods
MDM and MDSEC are also displayed.
Low complexity regions are shown in yellow and InterPro regions in green. Common (purple) and unique (grey) regions between different splice variants of the gene are also displayed (read more), and at the bottom of the protein view is the protein scale.
 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded