ARID1A
Search result
|
SINGLE CELL
SINGLE CELL TYPES
TISSUE CELL TYPE
SINGLE NUCLEI BRAIN
IMMUNE CELLS
EXPRESSION CLUSTER
TISSUES
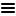
Cell type enrichment
Cell types
Methods
Brain cells
Cluster types
Methods
Immune cells
Immune cells
Methods
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded









